複雑なドメインモデルをシナリオで作る
信頼性の高いソフトウェアを継続的に開発し続けるためには、プロダクションコードの品質と同等かそれ以上にテストが重要になってきます。 テストは、ソフトウェアの品質を保証するための重要な要素であり、開発者がコードの変更を行う際に安心感を提供します。
HQ ではアプリケーションレベルでの結合テストを重視しています。 この記事では、結合テストを重視する理由と、結合テストの品質を向上させるためのシナリオに基づく宣言的なデータセットアップのアプローチについて紹介します。
SMURF
SMURF(Speed, Maintainability, Utilization, Reliability, Fidelity)は、テスト戦略を評価するための新しいフレームワークです。 Google Testing Blog の記事「SMURF: Beyond the Test Pyramid」で提案されました。
- Speed: テストの実行速度が速いこと。
- Maintainability: テストが簡単に保守・更新できること。
- Utilization: テストが実行されるマシンリソースが効率的に活用されていること。
- Reliability: テストが一貫して正確な結果を提供すること。
- Fidelity: テストが現実のシステム動作を正確に反映していること。
SMURF ではテストの種類(Unit, Integration, E2E)に対して、テスト特性を以下のチャートのように評価しています:
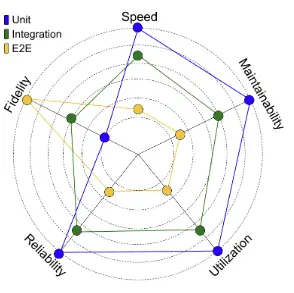
ざっくりまとめると
- 単体テストは速いけど Fidelity が低く実際の動作を反映していない可能性がある
- 結合テストはバランスが取れている
- E2E テストは Fidelity が高いけど遅くて保守が難しい
単体テストの Fidelity が低いのは、単体テストの性質と結び付いた本質的なものであり、改善することは難しいように思います。 一方、結合テストの Speed や Maintainability などを改善し単体テストに近づけていくことは可能なはずです。
HQ では大きくドメインモデルを書き直す機会も多く、そのような状況では単体テストがあまり役に立ちません。 このような観点からも、結合テストの比重を増やすことは理にかなっているように感じました。
NOTE
結合テストの速度を高めるために HQ ではテストサイズに着眼したアプローチをとっています。 この点については、改めてブログにて詳しく紹介する予定です。
結合テストの設計
テストはリファクタリング時など、記述されてから一定の時間が経ってから参照される機会も多くなるため、可読性や理解しやすさは重要な要素です。 特にリファクタリング時にテストが落ちた場合、そもそもそのテストが古くなっている可能性もあるため、テストの意図を読み解く必要があります。
テストの状況を適切に表現した名前をつけることが重要です。 しかし、どんなに良い名前をつけても、実際のテストコードが複雑であれば、そもそもその名前の通りに正しくテストされているのかどうかも分からなくなります。
シナリオ以前:モデルファクトリーによる手続的なデータセットアップ
長らくモデルファクトリーを使用した手続的なデータセットアップを用いてきました。 サンプルとして 1000 ポイントを持つユーザーが 800 ポイントのカタログアイテムをカートに追加し、チェックアウトできることを確認するテストを考えてみます。
t.Run("checking out a catalog item decreases the balance of a point account", func (t *testing.T) {
// おまじない
injector := setupDIInjector(t)
f := modelfactory.New(t, injector)
// 必要なドメインモデルを一つ一つ作っていく
org := f.CreateOrganization(t)
user := f.CreateUser(t, f.WithUserOrganization(org))
pointAccount := f.CreatePointAccount(t,
f.WithPointAccountUser(user),
f.WithPointAccountPeriodicDepositor(periodicDepositor),
)
pointAccount.Deposit(1000)
cart := f.CreateCart(t, f.WithCartUser(user))
catalogItem := f.CreateCatalogItem(t, f.WithCatalogItemAmount(800))
cart.AddCatalogItem(catalogItem)
// その上でテストの主題となる処理を実行する
usecase, _ := user_usecase.NewCheckoutCartWithInjection(context.Background(), injector)
_, err := usecase.Execute(world.Context(), user_usecase.CheckoutCartParams{
UserID: world.MustFindUser().UserID(),
CartID: world.MustFindCart().CartID(),
})
require.NoError(t, err)
// テストの結果を検証する
// ....
})
このアプローチはやることが単純だし何をしているかが分かりやすい反面、次第に以下のような問題が発生してきました:
- テストの主題と必ずしも関係がないセットアップコードも多く必要となりがち。このため、テストコード全体の可読性が低下し、理解が難しくなる。
- 作成しているモデルの組み合わせが正しくアプリケーションの状態を表現しているのかを保証するのが難しい。本来ならありえないデータでテストしている可能性があり、テストの信頼性に不安を感じることがある。
特にファクトリーの表現力を補うために次第に多くの副作用を持つ関数が作成されるようになり、テスト時にどのような状態になっているのかを把握するのが難しくなってきました。
シナリオによる宣言的アプローチ
この問題に対処するため、 HQ ではシナリオに基づく宣言的なデータセットアップのアプローチに試みています。 内部では以下の概念を用いて実装が行われています。
- World
- シナリオを実行する舞台となる世界を表現する構造体。
- 現在時刻をもち、時間経過とともに実行される cron ジョブを実行するなど、実世界のアプリケーションをカプセル化する。
- Libretto
- 台本を表現する構造体。
- いつ・どのシナリオを実行するかを格納する。
- Scenario
- テストの関心がある出来事を抽象化する。
全体としては「あるシナリオを実施して出来あがる世界」に対して、特定の手続が正しく動くのか、その手続きによって世界の状態は意図したものに変化したのかなどを確認します。
百聞は一見にしかずということで、実際のコードを見てみましょう。 上記と同じような状況を、シナリオを使って以下のように記述できるようになっています。
t.Run("checking out a catalog item decreases the balance of a point account", func (t *testing.T) {
catalogItemID := testutil.ID[purchasectx.CatalogItemID]("ITEM")
// libretto はテストのシナリオの台本を表現する構造体です。
libretto := testscenario.NewLibretto(t, testutil.JSTTime("2025-04-08 10:46")).
Then(
scenario_paragraph.CatalogItemCreated{
CatalogItemID: catalogItemID,
Amount: 800,
},
scenario_paragraph.OrganizationAndUserCreated{
PeriodicDepositAmount: 1000,
},
scenario_paragraph.CartEntryCreated{
CatalogItemID: catalogItemID,
},
)
world := testscenario.Play(t, libretto)
usecase, _ := user_usecase.MustNewCheckoutCartWithInjection(world.Context(), world.Injector())
// シナリオを実行した世界の上でテストの主題を実行します。
_, err := usecase.Execute(world.Context(), user_usecase.CheckoutCartParams{
UserID: world.MustFindUser().UserID(),
CartID: world.MustFindCart().CartID(),
})
require.NoError(t, err)
pointAccount := world.MustFindMainPointAccount()
require.EqualValues(t, 200, pointAccount.CurrentTotalBalance(world.Context()))
})
宣言的なアプローチを取ることにより、以下のようなメリットを感じています
テストの意図が明確になる
宣言的アプローチではテストの意図をシナリオという形でより直接的に表現します。 そのため、テストがどのような状況を想定したものであるかが明確になるため、テストの可読性が向上します。
例えば、上記のコードでは「カタログアイテムが作成され、ユーザーがカートに追加し、チェックアウトする」というシナリオを明示的に表現しています。 手続き的なコードと比較して、より直感的に意図を理解できるように思います。
テストが壊れにくくなる
通常、アプリケーションレベルの結合テストでは様々なドメインモデルを作成する必要があります。
仮に必要なドメインモデルが増えた場合、手続き的なアプローチでは新たな依存を作成するため多くのテストコードを修正しなければなりません。 短期的には手続きの中に変更を隠蔽できるかも知れませんが、この変更がもたらす副作用が、手続きを使う全ての箇所にとって望ましいものである保証はありません。
一方でシナリオに基づくアプローチでは、その状態を実現するための過程に変化があったとしても、その状態を実現する方法を隠蔽すること自体がまさにシナリオの責務であるため、修正することは意図したものです。
結果として、ドメインの変化に対して柔軟に対応できるようになり、テストコードが壊れにくくなります。
その他の話題
記事の長さの都合で詳細は割愛しますが、この他にも様々な工夫を行っています。
- アプリケーション上でのユーザーの行動は usecase として表現されており、個々のシナリオを分解していくと usecase にたどり着く。
- 実アプリケーションと全く同じコードがテスト環境で実行されることため、ドメインとしてあり得ない状態を誤って作成してしまうことがない。
- usecase からシナリオを自動生成している。
- 台本を実行する途中で失敗した際にどのシナリオで失敗したかを可視化することで、どこまでは実行できたのかを分かりやすく表示することができる。
- シナリオを使って開発環境のシードデータを作成している。
おわりに
HQ ではコンパウンドアプリケーションの開発を行っており、様々なドメインモデルが存在します。 そのため、ドメインモデルの変更に対して柔軟に対応できるようなテストコードが必要です。
シナリオに基づく宣言的なデータセットアップのアプローチは、テストの可読性や保守性を向上させるだけでなく、ドメインモデルの変更に対しても柔軟に対応できるようになります。 このアプローチを採用することで、テストコードの品質を向上させ、信頼性の高いソフトウェアを継続的に開発し続けることができると考えています。
そしてテスト品質の向上は、開発スピードの向上につながり、結果としてより良いソフトウェアの提供へとつながります。
このアプローチはまだ試行錯誤の段階ですが、今後も改善を続けていきます。
